- · 《产业与科技论坛》栏目[05/29]
- · 《产业与科技论坛》数据[05/29]
- · 《产业与科技论坛》收稿[05/29]
- · 《产业与科技论坛》投稿[05/29]
- · 《产业与科技论坛》征稿[05/29]
- · 《产业与科技论坛》刊物[05/29]
一、来稿必须是作者独立取得的原创性学术研究成果,来稿的文字复制比(相似度或重复率)必须低于用稿标准,引用部分文字的要在参考文献中注明;署名和作者单位无误,未曾以任何形式用任何文种在国内外公开发表过;未一稿多投。 二、来稿除文中特别加以标注和致谢之外,不侵犯任何版权或损害第三方的任何其他权利。如果20天后未收到本刊的录用通知,可自行处理(双方另有约定的除外)。 三、来稿经审阅通过,编辑部会将修改意见反馈给您,您应在收到通知7天内提交修改稿。作者享有引用和复制该文的权利及著作权法的其它权利。 四、一般来说,4500字(电脑WORD统计,图表另计)以下的文章,不能说清问题,很难保证学术质量,本刊恕不受理。 五、论文格式及要素:标题、作者、工作单位全称(院系处室)、摘要、关键词、正文、注释、参考文献(遵从国家标准:GB\T7714-2005,点击查看参考文献格式示例)、作者简介(100字内)、联系方式(通信地址、邮编、电话、电子信箱)。 六、处理流程:(1) 通过电子邮件将稿件发到我刊唯一投稿信箱(2)我刊初审周期为2-3个工作日,请在投稿3天后查看您的邮箱,收阅我们的审稿回复或用稿通知;若30天内没有收到我们的回复,稿件可自行处理。(3)按用稿通知上的要求办理相关手续后,稿件将进入出版程序。(4) 杂志出刊后,我们会按照您提供的地址免费奉寄样刊。 七、凡向文教资料杂志社投稿者均被视为接受如下声明:(1)稿件必须是作者本人独立完成的,属原创作品(包括翻译),杜绝抄袭行为,严禁学术腐败现象,严格学术不端检测,如发现系抄袭作品并由此引起的一切责任均由作者本人承担,本刊不承担任何民事连带责任。(2)本刊发表的所有文章,除另有说明外,只代表作者本人的观点,不代表本刊观点。由此引发的任何纠纷和争议本刊不受任何牵连。(3)本刊拥有自主编辑权,但仅限于不违背作者原意的技术性调整。如必须进行重大改动的,编辑部有义务告知作者,或由作者授权编辑修改,或提出意见由作者自己修改。(4)作品在《文教资料》发表后,作者同意其电子版同时发布在文教资料杂志社官方网上。(5)作者同意将其拥有的对其论文的汇编权、翻译权、印刷版和电子版的复制权、网络传播权、发行权等权利在世界范围内无限期转让给《文教资料》杂志社。本刊在与国内外文献数据库或检索系统进行交流合作时,不再征询作者意见,并且不再支付稿酬。 九、特别欢迎用电子文档投稿,或邮寄编辑部,勿邮寄私人,以免延误稿件处理时间。
特别推荐 | TechBeat技术社区7月文章精选
作者:网站采编关键词:
摘要:关注并星标 从此不迷路 Jiangmen 每周追大佬的Talk之余,在TechBeat技术社区里还有很多干货文章供大家浏览学习:无论是各大顶会学术论文的深度解读,还是技术在各个行业中的落地场景
关注并星标
从此不迷路
Jiangmen

每周追大佬的Talk之余,在TechBeat技术社区里还有很多干货文章供大家浏览学习:无论是各大顶会学术论文的深度解读,还是技术在各个行业中的落地场景的前沿分享,你都可以找到!今天就让我“门”来盘点一下,
7月都有哪些精彩文章吧!
关注TechBeat社区 () ,还有更多干货文章、技术Talk与你分享~
文章在哪儿?
复制链接 w 到浏览器,
选择【文章】,即可查看所有干货内容啦!

1
万字详解:腾讯如何自研大规模知识图谱 Topbase

作者:腾讯TEG应用研究员-郑孙聪
Topbase是由腾讯TEG-AI平台部构建并维护的一个专注于通用领域的知识图谱,其主要应用于大家所熟知的微信搜一搜、信息流推荐及智能问答产品。本文主要梳理了Topbase构建过程中的技术经验,从0到1地介绍了构建过程中的重难点问题以及相应的解决方案,希望对图谱建设者有一定的借鉴意义。
本文链接:
2 当谈论法律智能技术,
我们可以谈论些什么?

作者:清华大学计算机系副教授-刘知远
清华大学计算机系硕士-钟皓曦
当人工智能技术广泛应用于股票走势预测、智慧医疗等工作时,近几年也有不少研究者尝试将其应用于法律领域——这个拥有大量数据积累的方向上。本文将从什么是法律智能入手,来介绍整个法律智能的发展,现状以及它的未来,希望能够帮助对法律智能研究感兴趣的朋友。
本文链接:
3 深度卷积网络中的卷积算子研究进展
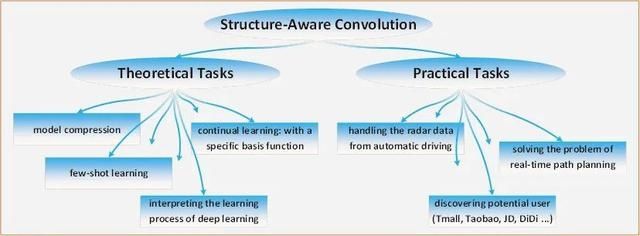
作者:中科院自动化所·在读博士生-常建龙
在各种深度神经网络结构中,作为应用最为广泛的卷积神经网络,可以利用有效的参数共享方式,保证模型的性能大量地减少模型参数。本文中,作者着重介绍了通过一般化传统卷积的操作,使得新的卷积神经网络可以应用到一般结构的数据上,而不是仅局限于处理欧几里得空间的数据。
本文链接:
4 标注样本少怎么办?
「文本增强+半监督学习」总结

作者:零氪智能科技(LinkDoc)-娄杰
本文主要介绍的是半监督学习,关注如何利用领域相关的未标注数据,与此相关的是主动学习,致力于挖掘高价值样本。在整体的少样本解决方案中,还有多任务学习、领域自适应、以及大家比较关注的few-shot等,few-shot在NLP领域还不成熟,性能表现和数据集的构建密不可分,其更注重未知标签的判别,在现实落地上还有一段距离。
本文链接:
5 医疗健康领域的短文本纠错

作者:丁香园 NLP算法工程师-Qarnet
都说在NLP领域文本纠错是个坑。因为目前没有特别成熟的方法,而且用到的知识点比较繁琐,真正的应用到工业界还要考虑实际成本和效率等问题,常见的纠错内容可能时常让人啼笑皆非。在丁香园医疗垂直领域的文本纠错实验中,团队调研一些学术界近期的结果和工业界常规方法,尝试去解决用户在使用搜索引擎带来的纠错问题。
本文链接:
6 朴素贝叶斯:帮助AI产品经理
“小步快跑,快速迭代”

作者:平安科技·资深产品经理-林中翘
贝叶斯定理相信不少人都接触过,这个看似只属于数学领域的定理,在AI产品经理看来有怎样的魅力呢?本文中,作者通过梳理“贝叶斯定理”概念,抛出一个“真假概率”的小实验,进而阐述出产品经理的思考方式——或许,“小步快跑,快速迭代”才是提升容错率最好的办法!
本文链接:
7 CVPR 2020
利用自适应边际损失增强小样本学习

作者:华为诺亚方舟实验室研究员-黄维然等
本文从 CV 和 NLP 多模态的视角切入,通过考虑类别的语义信息来提升小样本学习的性能。在进行大量实验后,文中所述方法在标准小样本分类和广义小样本分类任务上都显著超越了现有的方法!
文章来源:《产业与科技论坛》 网址: http://www.cyykjltzz.cn/zonghexinwen/2020/0801/476.html